
Durante el estudio de la Arquitectura de Computadores, el concepto de “Pipeline” puede que sea dado a omitir por los programadores, no obstante, debe ser algo conocido en su máxima teoría la referencia a este concepto en términos de Arquitecturas de Computadores.
A continuación, se explicarán algunos términos referentes al mencionado.
Pipeline ¿Qué es?
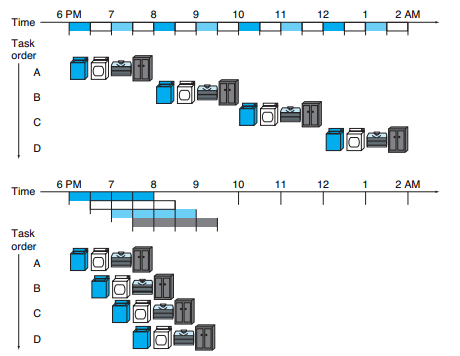
La canalización (Pipeline) es una técnica de implementación en la que se imparten múltiples instrucciones. Se superpusieron en la ejecución. Hoy en día, el pipeline es casi universal, siendo la entrada de cada una la salida de la anterior, con un almacenamiento temporal de datos entre procesos. Entender cómo funciona un pipeline es un paso importante para entender qué ocurre dentro de un procesador. Este sistema es común verlo en sistemas operativos multitarea ya que puede ejecutar una serie de procesos de manera simultánea, los cuales son ejecutados de manera secuencial mediante un administrador de tareas que aplica distintos tipos de prioridad y capacidad de procesamiento.
Ciclo de vida de una instrucción La acción básica de cualquier microprocesador, en tanto se mueva a través de la corriente de instrucciones, se puede descomponer en 4 pasos, que cada instrucción en la corriente de código se debe atravesar para poder ejecutarse con éxito:
- Fetch: Se encarga de “traer” la instrucción que se debe ejecutar, de la dirección que está almacenada en el contador del programa.
- Store: Se encarga de “guardar o almacenar” la instrucción en el registro de instrucciones y luego “descifrarla”, incrementando la dirección en el contador de programa.
- Execute: Se ejecuta la instrucción almacenada en el registro de instrucciones. Si la instrucción no es una instrucción de rama si no una instrucción aritmética, este proceso la envía la ALU donde el microprocesador “lee” el contenido de los registros de entrada y “agrega” el contenido de los registros de entrada.
- Write: “escribe” los resultados de esa instrucción dentro del registro de destinación.
En un proceso moderno, los cuatro pasos son repetidos una y otra vez hasta que el programa termine de ejecutarse.
Pipeline Hazards Como es de saber, en toda situación pueden ocurrir percances, y en este caso puede ocurrir porque puede que la siguiente instrucción no se pueda ejecutar en el directorio siguiendo el ciclo del reloj. Por lo tanto, ingresan 3 peligros y son los siguientes.
· Structural Hazards: El primer peligro se llama riesgo estructural (Structural Hazards). Significa que el hardware no puede soportar la combinación de instrucciones que queremos ejecutar en un mismo reloj ciclo.
· Data Hazards: Los peligros de datos ocurren cuando la tubería debe detenerse porque un paso debe esperar para que otro lo complete.
· Control Hazards: El tercer tipo de peligro se denomina peligro de control, que surge de la necesidad de hacer una decisión basada en los resultados de una instrucción mientras se ejecutan otras.
Referencias
Hennessy, John L. (13 de octubre de 2011). Computer Organization and Design. (4a ed., pp. 335, 336, 339).
Nuñez, Tomas. (18 de abril de 2018). Electrontools. Modelo de Arquitectura Pipeline. MODELO DE ARQUITECTURA PIPELINE - Tutoriales de Electrónica | Matemática y Física (electrontools.com)